Background
The reverberation is known to degrade severely the audible quality of speech signal and performance of automatic speech recognition (ASR). While a range of signal processing and speech recognition techniques are available for combatting the effect of additive noise, the development of practical algorithms that can reduce the detrimental effect of reverberation has been one of the holy grails for a long time.
In recent years, research on reverberant speech processing has achieved significant progress in both the fields of audio processing and speech recognition, mainly driven by multidisciplinary approaches combining ideas from room acoustics, optimal filtering, machine learning, speech modeling, enhancement, and recognition. Now these novel techniques seem to be ready to be evaluated for real-world speech enhancement and speech recognition applications.
Goal of this challenge
The goal of the REVERB challenge is to evaluate novel and established speech enhancement and recognition techniques in reverberant environments, provide an opportunity to the researchers in relevant fields to carry out comprehensive evaluation of their systems based on common data sets, and enable fair and reasonable comparison of different approaches, aiming at providing new insights into the problem and facilitating clear understanding of the state of the art.
Target scenario : Recording conditions
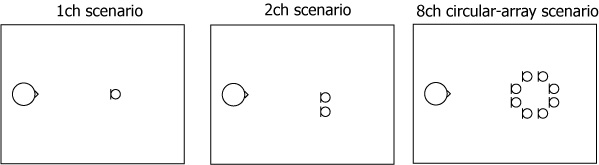
The challenge assumes the scenario of capturing utterances spoken by a single stationary distant-talking speaker with 1-channel (1ch), 2-channel (2ch) or 8-channel (8ch) microphone arrays in reverberant meeting rooms as shown in the following figures. It features both real recordings (RealData) and simulated data (SimData), a part of which simulates the real recordings. More details about the challenge data are given in the Data section.
Fig: Scenarios assumed in the challenge